
至强 6 性能核处理器在核数、内存带宽均大幅提高的加持下,推感性能激增瘦猴 探花,进一步提高了推理的性价比。
至强 6 性能核的中枢界限
在之前的著述中,有从业者忖度至强 6 性能核处理器每颗盘算推算单位芯片中的内核数目为 43,加上每个盘算推算单位有两组双通谈内存落幕器各占一个网格,那么统共占用 43+2=45 个网格,可以由 5×9 的布局组成。但这个假定有一个问题,要组成 128 核的 6980P,三颗芯片只屏蔽 1 个内核,这良率条目比较高啊。

于今还未在公开渠谈看到至强 6 性能核处理器的 Die shot 或架构图,但英特尔发布了晶圆相片算作宣传素材。天然晶圆相片并不成提供每颗芯片的明晰信息,但浮泛能嗅觉到,网格组成更像是 5×10,而不是 5×9 或 6×8。另外,左上角和左下角疑似内存落幕器的区域面积比意想的要大得多,每一侧占了三个网格。如果吸收了两组内存落幕器共占用 6 个网格的设定,那么每个芯片中等于 50-6=44 个内核,在组成 6980P 的时候分别屏蔽一到两个核即可,嗅觉就合理多了。

在获取相对真确的内核数目后,新的狐疑等于:为什么至强 6 性能核的内存落幕器这样占地 —— 这个区域有其他未知功能?照旧因为增多了 MRDIMM (Multiplexed Rank DIMM) 的搭救?毕竟在此之前,英特尔的双通谈 DDR5、三通谈 DDR4 内存落幕器只占一个网格,以致,连信号界限更大、带宽更高的 HBM 落幕器(至强 CPU Max 处理器)亦然一个网格。至强 CPU Max 处理器的 HBM2e 是责任在 3,200MT/s,那么每个落幕器带宽是 410GB/s,整颗 CPU 有跨越 2TB/s 的 HBM 带宽。
天然对疑似内存落幕器区域所占芯单方面积的狐疑未解,还需要进一步解惑,但至少可以笃定,英特尔在这一代至强的内存落幕器上是下了大资本的。至少在尽头一段时辰内,它是可以 “独占” MRDIMM 的上风了。
至强 6 性能核的 NUMA 与集群模式
谈行状器的内存就绕不外 NUMA(Non-Uniform Memory Access,非息争内存探访)。因为跟着 CPU 内核数目的增多,各内核的内存探访肯求恣虐会赶紧增多。NUMA 是一个灵验的惩处决策,将内核分为多少组,分别领有相对沉寂的缓存、内存空间。界限减轻后,恣虐就会减少。一般来说,NUMA 分离的原则是让物理上附进某内存落幕器的内核为一个子集。这个子集被英特尔称为 SUB-NUMA Clustering,简称 SNC。统一 SNC 的内核绑定了末级缓存(LLC)和腹地内存,探访时的时延最小。
比方,在第三代至强可推广处理器中,一个 CPU 内可分离两个 SNC 域,每个 SNC 对应一组三通谈 DDR4 内存落幕器。如果关闭 NUMA,那么通盘 CPU 的内存将对称探访。
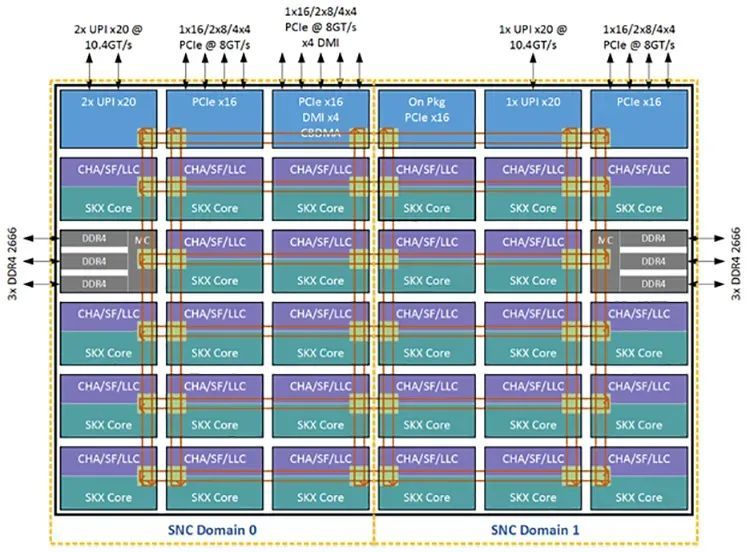
而第四代至强可推广处理器使用了 4 颗芯粒的封装,可以被分离为 2 个或 4 个 SNC 域。如果但愿每个内核可以探访通盘的缓存代理和内存,可以将第四代至强可推广处理器开垦为 Hemisphere Mode 或者 Quadrant Mode,默许是后者。第五代至强可推广处理器是 2 颗芯粒,可以分离为两个 SNC 域。
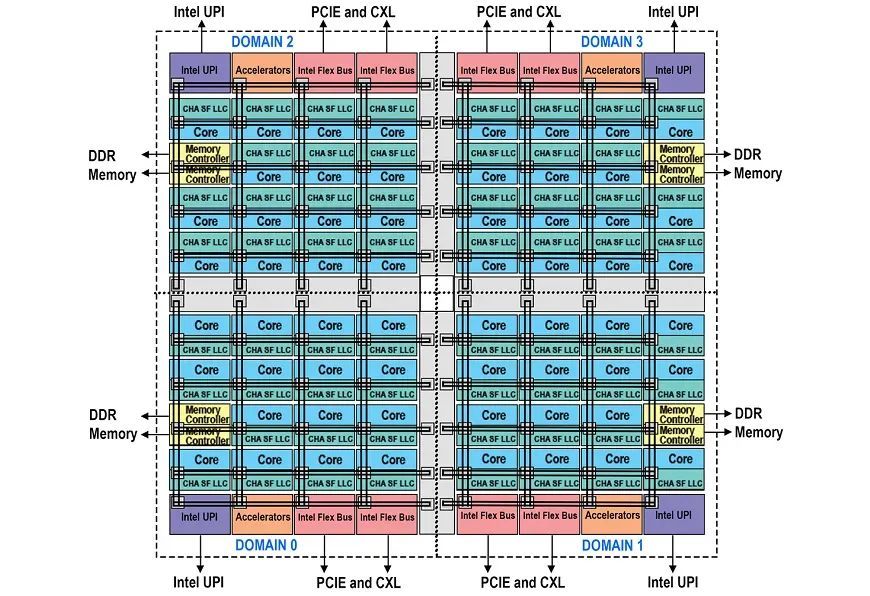
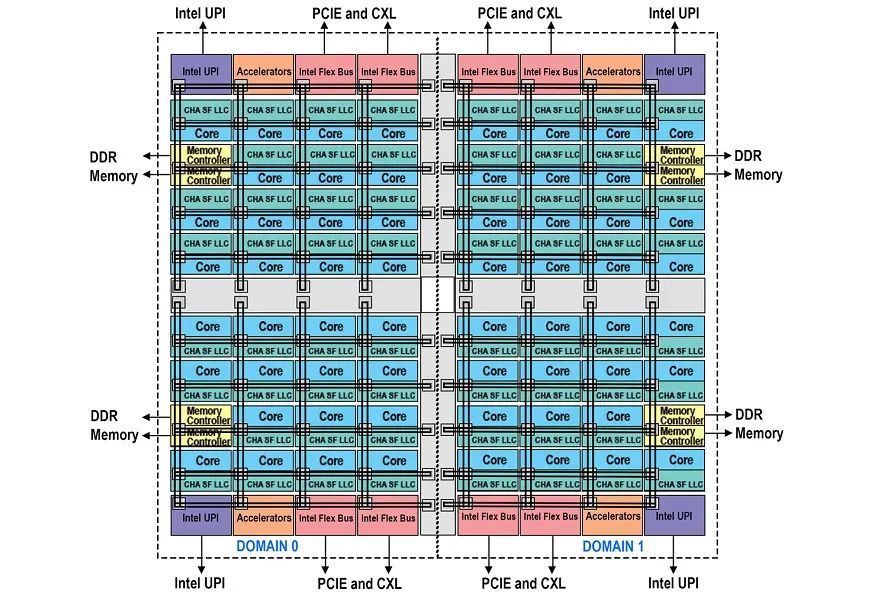
在至强 6 性能核中,可以将每个盘算推算单位芯片算作一个 SNC,每个域领有 4 个内存通谈,这被称为 SNC3 Mode。如果要通过其他芯粒的缓存代理探访通盘内存,那等于 HEX Mode。

左证英特尔提供的数据,几种不同模式的内存探访时延各异较大,与内核、内存落幕器之间的 “距离” 径直有关。至强 6 性能核的内核界限、内存落幕器数目增多之后,相应的探访时延也会飞腾。举例,左证前边的不雅察,至强 6 性能核内每个盘算推算单位芯片中,内核与内存落幕器的最远距离为 10 列,而第四代 / 第五代至强可推广处理器无 NUMA 的为 8 列。这反应在英特尔的数据上,等于至强 6900P 在 SNC3 Mode 的时延略高于上一代至强处理器的 Quad Mode。如果至强 6900P 设为 HEX Mode,那么内核与内存落幕器的最远距离将达到 13 以致 15 列,时延增多会比较显着。
举座而言,由于 SNC3 Mode 时延低,其将成为至强 6 行状器的默许模式。这种模式主如果合乎臆造化 / 容器化这类常见云应用,以及并行化历程高的盘算推算(如编解码)等。天然,HEX Mode 可以径直探访更大界限的内存,这关于大型数据库,尤其所以 OLTP 为代表的应用来说更为故意。Oracle 和 SQL 频繁冷漠关闭 NUMA 以获取更佳的性能。Apache Cassandra 5.0 这类引入向量搜索的数据库也能从 HEX Mode 显贵获益。部分科学盘算推算也更合乎 HEX Mode,比方通过偏微分方程建模的 PETSs、分子能源学软件 NAMD 等。
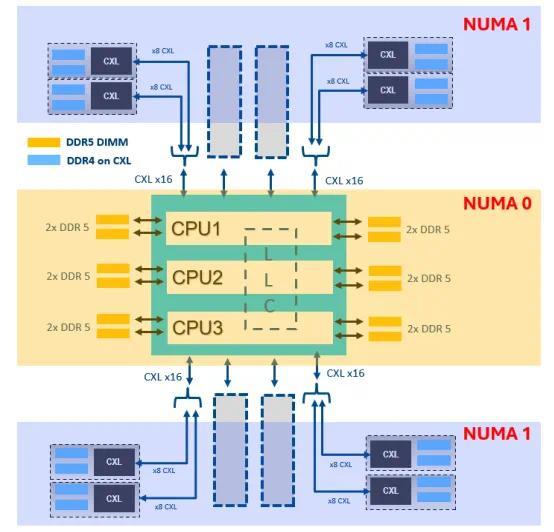
HEX Mode 的另一个典型场景是合作 CXL 内存使用。比方英特尔在本年 12 月 11 日发布的一篇讹诈 CXL 内存优化系统内存带宽的论文中,使用了至强 6900P 搭配 12 条 64GB DDR5 6400 以及 8 个 128GB CXL 内存模块,其中至强 6900P 腹地的 768GB DDR5 内存在 HEX Mode 下建树为 NUMA0,通盘的 1TB CXL 内存建树为 NUMA1,采选优化交错建树(Interleaving Strategy)。测试标明,在内存带宽明锐的应用中,使用 CXL 内存推广可以提高 20%~30% 的性能。
MRDIMM 领跑者
关于至强 6 性能核处理器而言,提高内存带宽最径直的法子莫过于 MRDIMM。这亦然这款处理器比较其他同类居品比较独占的一项才略,近期看不到任何其他 CPU 厂商有明确搭救 MRDIMM 的时辰表,更不要说推出践诺居品了。相对而言,内存厂商对 MRDIMM 的搭救比较积极,好意思光、SK 海力士、威刚齐推出了相应的居品,包括高尺寸(Tall formfactor,TFF)。第一代 DDR5 MRDIMM 的计算速率为 8,800 MT/s,畴昔会冉冉提高至 12,800 MT/s、17,600 MT/s。
MRDIMM 增多了多路复用数据缓冲器(MDB),改良了寄存时钟驱动器(MRCD)。MDB 吩咐在内存金手指近邻,与主机侧的 CPU 内存落幕器通信。MDB 主机侧的运行速率是 DRAM 侧的双倍,DRAM 侧的数据接口是主机侧的双倍。MRCD 可以生成 4 个沉寂的芯片采选信号(措施的 RCD 是两个,对应两个 Rank)。MDB 可通过两个数据接口将两个 Rank 分别读入缓冲区,再从缓冲区一次性传输到 CPU 的内存落幕器,由此已毕了带宽翻倍。

由于 MRCD 可以搭救 4 个 Rank,也意味着可以搭救双倍的内存颗粒。依然展示的 MRDIMM 多数引入更高的板型(TFF),单条容量也由此倍增。由于至强 6900P 插座尺寸大增,导致双路机型的内存槽数目从上一代的 32 条减少到 24 条。要能够连接推广内存容量,增多内存条的面积(增多高度)确乎是最简便径直的技能。通过使用 256GB 的 MRDIMM,双路至强 6900P 机型可以获取 6TB 内存容量。除了更大的内存带宽,更高的内存容量也相配故意于 AI 查验、大型数据库等应用的需求,进一步强化至强 6900P 在 AI 机头领域的上风。
与 DDR5 6,400MT/s 比较,MRDIMM 8,800MT/s 的践诺运行频率略低(4,400MT/s),导致轻量级的应用不成从内存带宽的增多当中显着获益。其实同样的问题在内存代际转机之初均会存在,能够充分讹诈更大内存带宽的主要照旧盘算推算密集的应用,比方加密、科学盘算推算、信号处理、AI 查验和推理等。从当今的测试看,对 MRDIMM 受益最大的应用主要包括 HPCG(High Performance Conjugate Gradient)、AMG(Algebraic Multi-Grid)、Xcompact3d 这些科学盘算推算类的应用,以及谎言语模子推理。
内存带宽与大模子推理
上一节有提到,并非通盘应用齐能充分讹诈 MRDIMM 的内存带宽收益。就本节重心要谈的推理当用而言,左证当今所见的测试数据,卷积神经相聚为代表的传统推理任务在 MRDIMM 中获取的收益就比较小,不到 10% 的水平。而在谎言语模子推理当中,MRDIMM 的带宽上风将得到充分的推崇,性能提高在 30% 以上,因为大模子是笃定性的渴求显存 / 内存容量和带宽的应用场景。
在这里就得提一下英特尔至强 6 性能核处理器发布会贵府中的另一个细节:在多种责任负载的性能对比中,AI 部分的提高幅度最为显着,况且仅用了 96 核的型号(至强 6972P)。
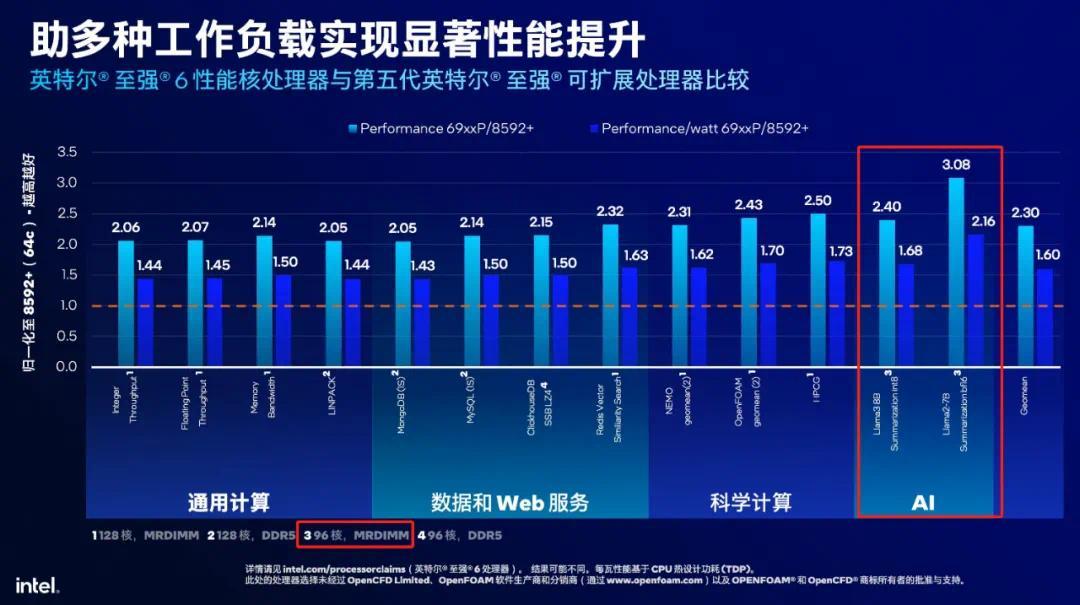
也等于说,至强 6972P 使用了至强 8592 + 的 1.5 倍内核,获取了至少 2.4 倍的谎言语模子推感性能。其中,右侧的是 Llama3 8B,int8 精度,那么模子将占用约 8GB 的内存空间。以当今双路 24 通谈 MRDIMM 8,800MT/s 约 1,690GB/s 的总内存带宽而言,可以算出来每秒 token 数表面上限是 211。而双路 8592 + 是 16 通谈 DDR5 5,600MT/s,内存总带宽为 717GB/s,token 表面上限是接近 90。二者的表面上限恰恰出入简短 2.4 倍。在这个例子当中,内存带宽的增长幅度显着大于 CPU 内核数目的增长。也等于说,在假定算力不是瓶颈的情况下,内存或显存容量决定了模子的界限上限,而带宽决定了 token 输出的上限。
美女车模一般来说,在落幕模子参数目并进行低精度量化(int8 以致 int5、int4)之后,谎言语模子推理时的算力瓶颈依然不太荒芜,决定并发数目和 token 响应速率的,主要照旧内存的容量和带宽。通过 MRDIMM,以及 CXL 内存推广带宽将是提高推感性能最灵验的阵势。这亦然当今 CPU 推理依旧受到爱重的原因,除了可获取性、资源弹性外,在内存容量及带宽的推广上要比 VRAM 低廉的多。
结语
跟着掌捏更多的信息,至强 6 性能核处理器在内存带宽上的上风和后劲显得愈发明晰了。MDRIMM 不但能够大幅提高内存带宽,还能使可部署的内存容量翻倍,显贵利好传统的重担荷领域,如科学盘算推算、大型数据库、营业分析等,关于新兴的向量数据库也大有裨益。CXL 还能够进一步起到镌脾琢肾的作用。
曩昔几年,增长迅猛的大模子推理需求,让至强可推广处理器(从第四代开动)讹诈 GPU 缺货的机会说明了在 AMX 的加持下,纯 CPU 推理也有可以的性能,况且易于采购和部署。跟着应用深化,部分互联网企业还挖掘了 CPU 推理的资源弹性,与传统业务同构的硬件更易于进行峰谷治愈。至强 6 性能核处理器在核数、内存带宽均大幅提高的加持下,推感性能激增,进一步提高了推理的性价比。在惩处了 “能或不成” 的问题之后,推理成本是谎言语模子落地后最要津的挑战。不详在这方面,至强 6 性能核处理器配 MRDIMM 的组合,将会带来一些新的解题想路。
© THE END瘦猴 探花
Powered by 伦理片在线观看影院麒麟 @2013-2022 RSS地图 HTML地图
Copyright Powered by365站群 © 2013-2024